library(amcat4r)
amcat_login("http://localhost/amcat")3 Document Storage
This chapter covers how you can upload, change, query, and delete documents and indexes in AmCAT. Some basic tasks are implemented in the Web user interface, for the rest you need to use one of the clients in R or Python or another means to call the API (e.g., through cURL as shown below). You can also use the API calls to build your own client.
More information on the API can be found on every amcat4 instance at /redoc (e.g., http://localhost/amcat/redoc).
Let us know about it and we will promote your new API wrapper package here.
3.1 Manage Documents with the Graphic User Interface
3.1.1 Upload
From the Graphic User Interface (GUI), you can “Create an Index” by uploading it as a csv file.
Navigate to your favorite spreadsheet (e.g. Excel) and create something that resembles the following:
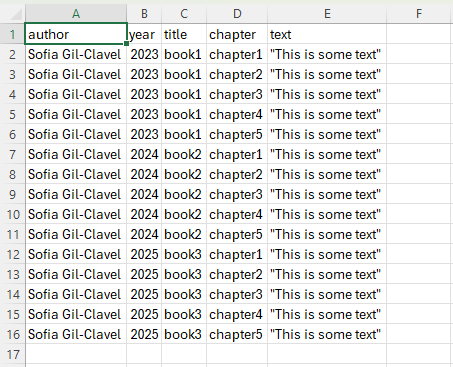
Save it as csv utf-8:

Upload it to AmCAT:
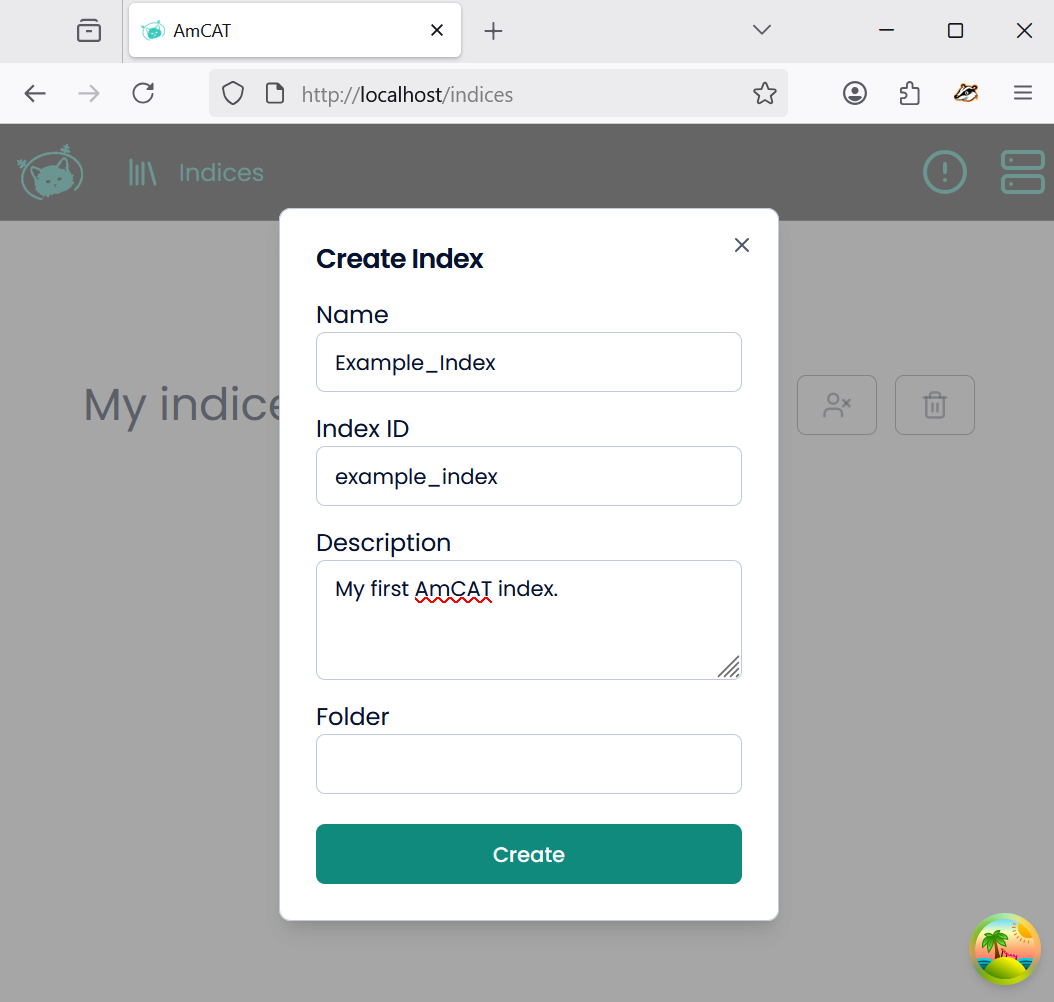
Fill out each option and press “Create”:
That will display a window with the following information:
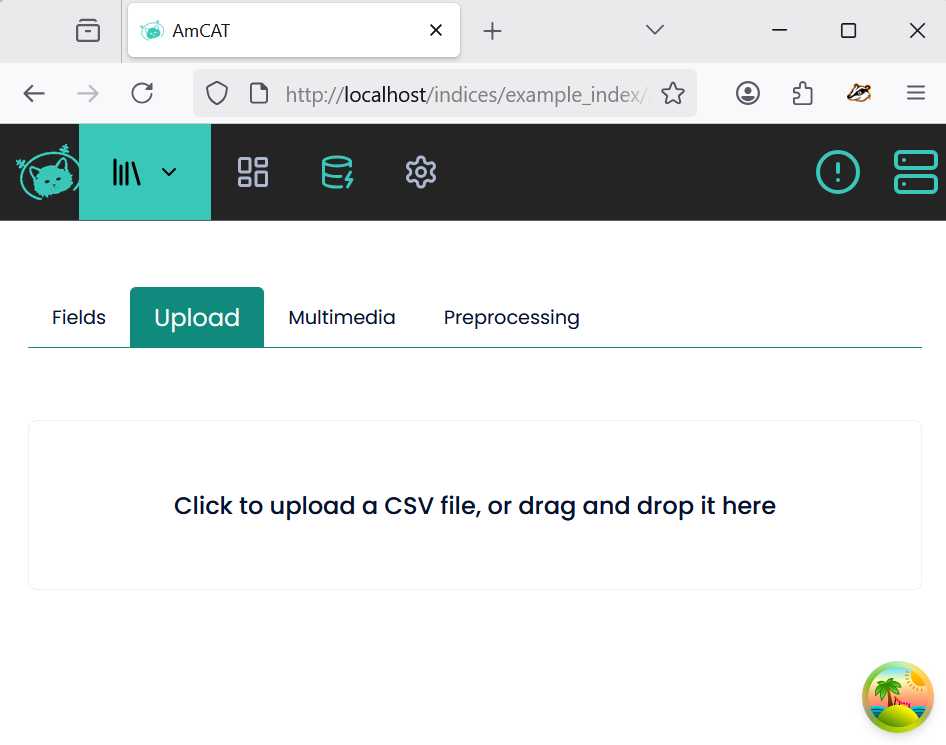
Now, you can just drag and drop the csv file into the window:
This will display a window with the following information:
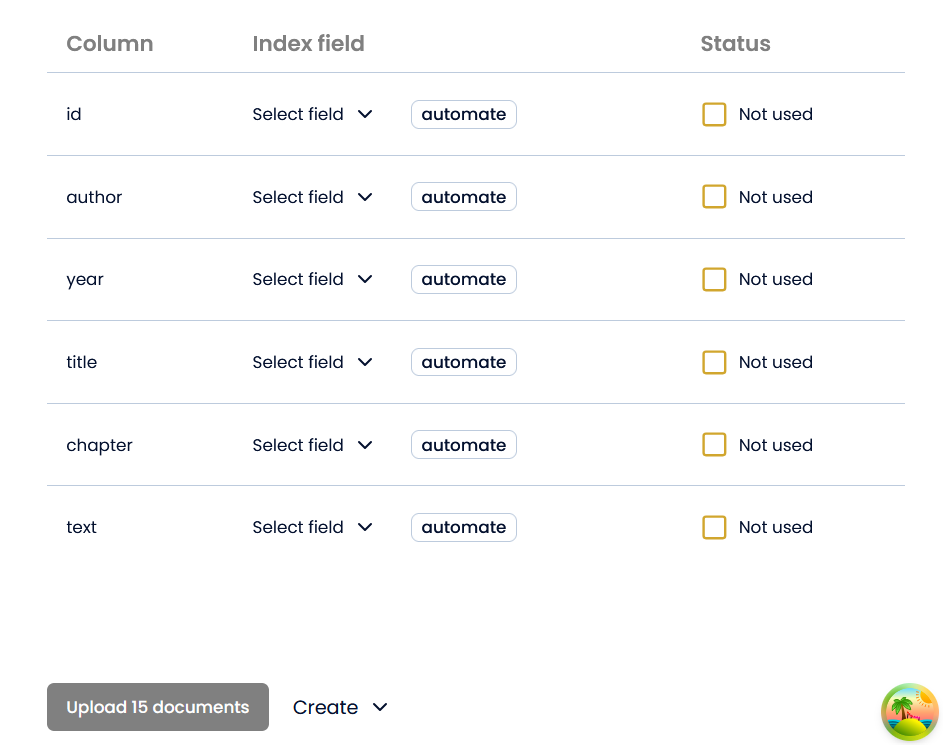
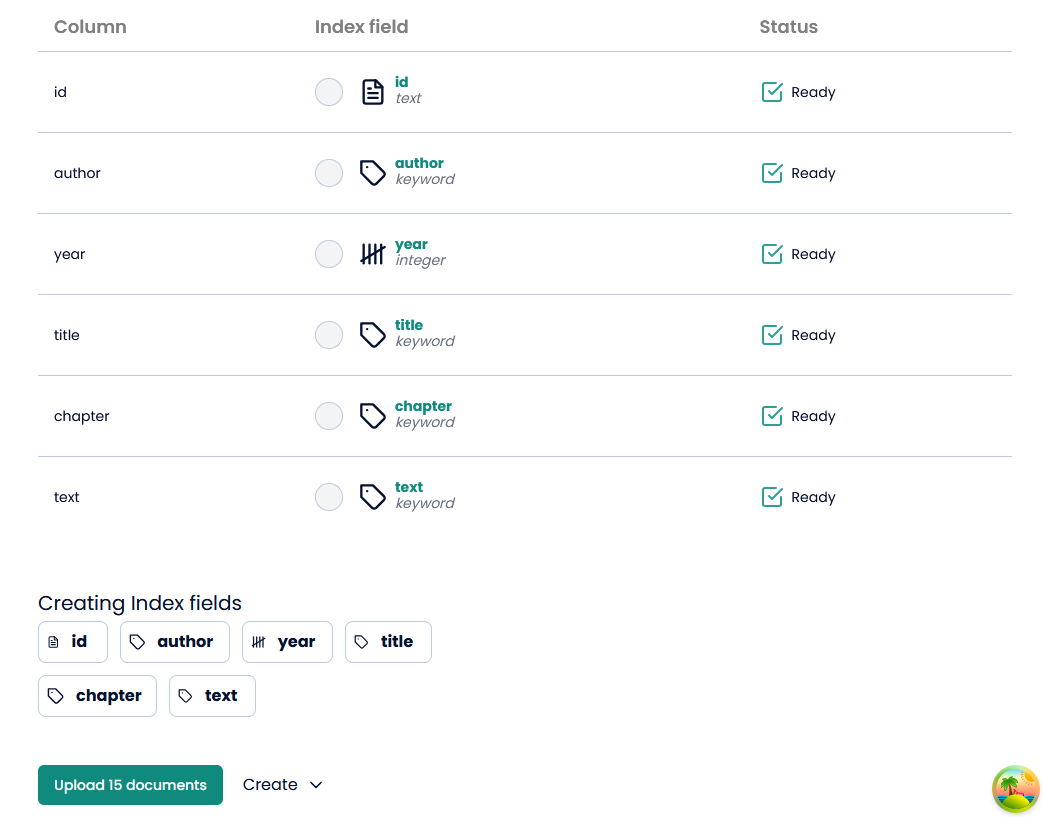
From there, you can either choose the type of field by clicking “Select field” or let AmCAT do it for you by clicking “automate”. If in doubt, then choose “automate”. Clicking “automate” on all gives the following result:
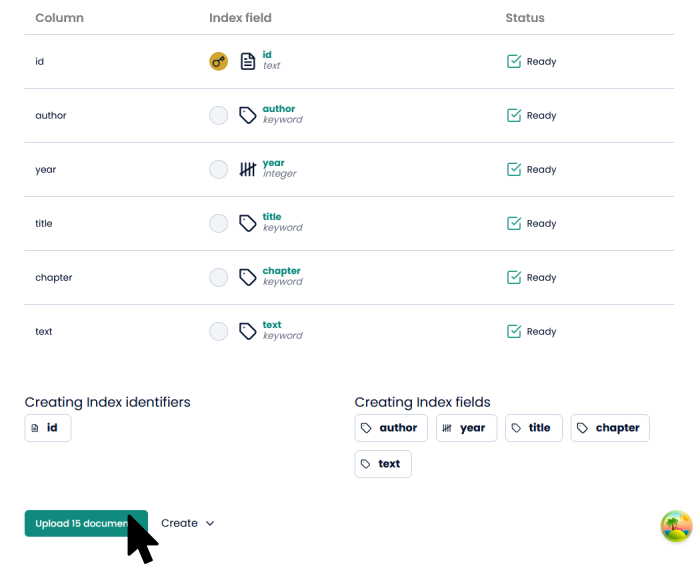
You have to explicitly choose the column(s) that will be used to create the unique identifier. In this example, I explicitly created a column named “id”. So, that is the one I chose as identifier:

Now, you can press “Upload 15 documents”, which is the number of rows in the csv file.
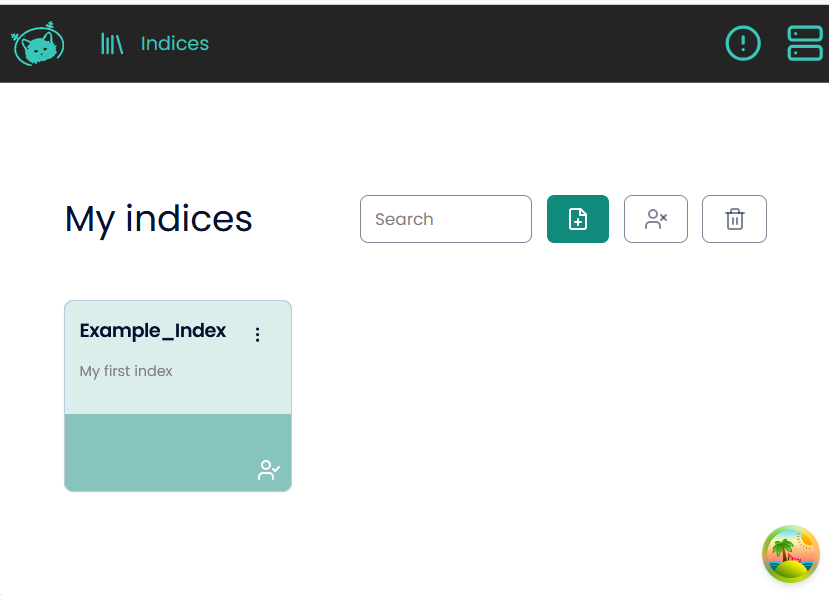
Now you can navigate to your indeces and find your newly made index:
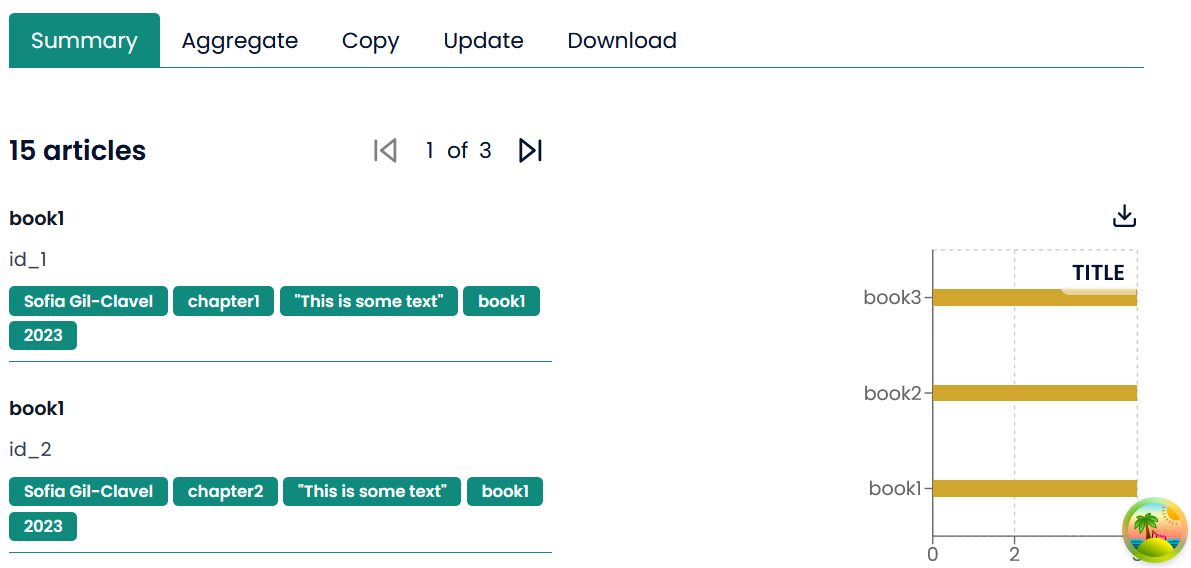
3.1.2 Visualize
One of AmCAT features is that it allows you to perform some basic visualizations. To do so in the main window, you first need to enable them.
For this, you just need to click on “Enable visualizations in field settings”.
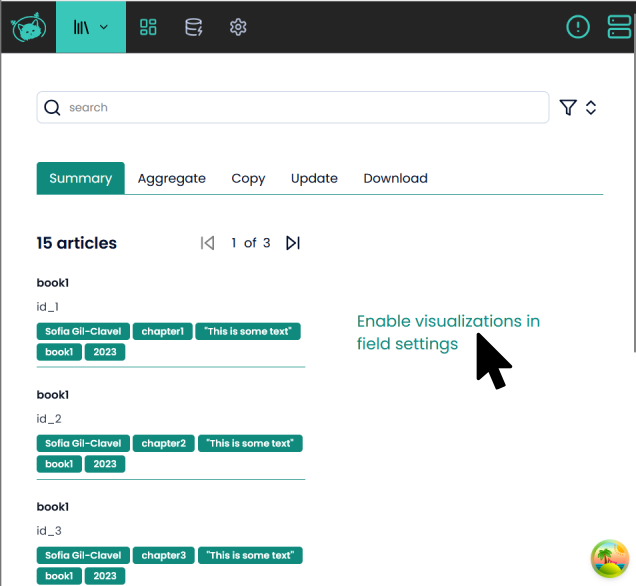
That will open the following window:
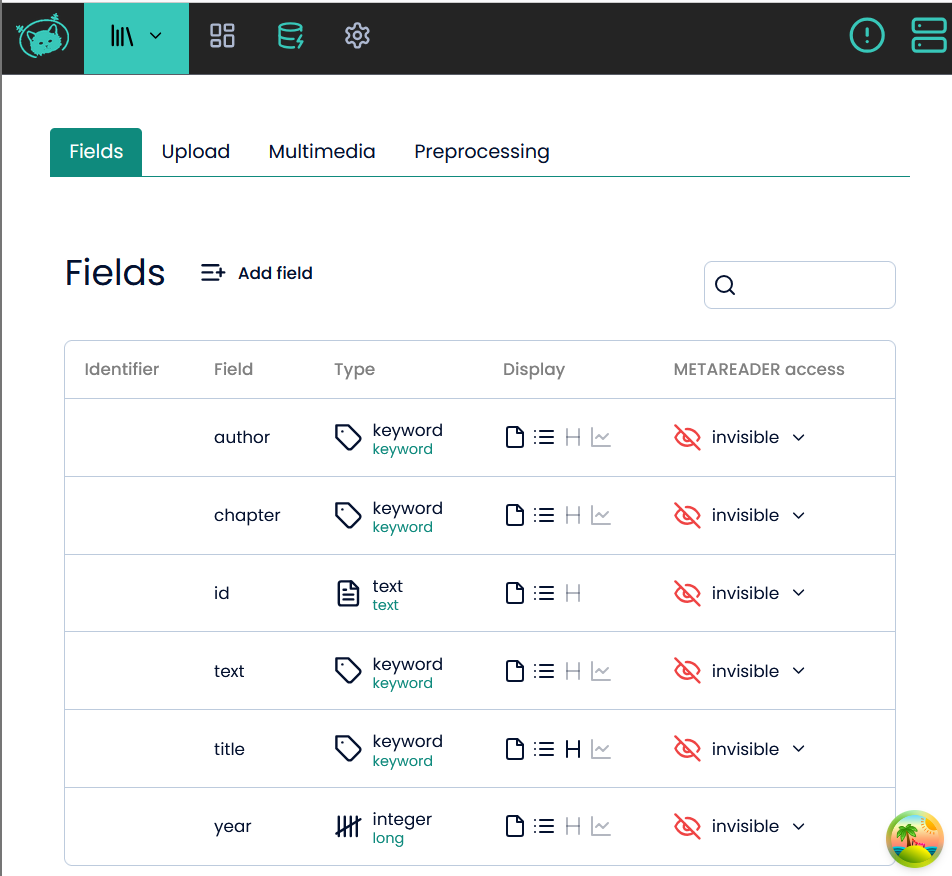
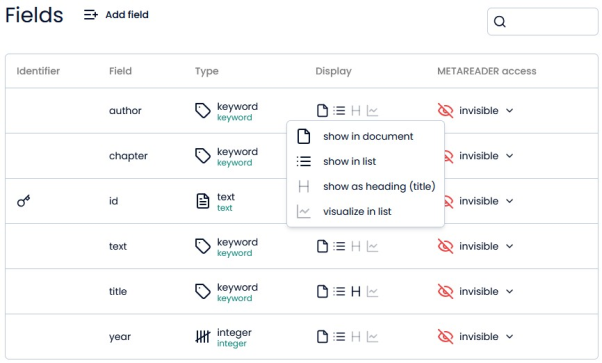
From there, you just need to click on the fields  , under the column “Display”, and choose the options “show as heading” and/or “visualize in list”.
, under the column “Display”, and choose the options “show as heading” and/or “visualize in list”.
You can go back to the main window by clicking on “Dashboard”  . There you can see the visualizations you have enabled:
. There you can see the visualizations you have enabled:
3.2 Manage Documents with the API
For this overview, we log into a local amcat4 (i.e., http://localhost/amcat). Replace this with the address to the amcat4 instance you are working with (e.g., https://opted.amcat.nl/api).
We first need to log in:
from amcat4py import AmcatClient
amcat = AmcatClient("http://localhost/amcat")
if amcat.login_required():
amcat.login()There is no dedicated way at the moment to get a token via cURL. You can still use cURL with instances that do not require authentication or by copying the token from Python or R. In these cases, you can make requests with an extra header, for example:
AMCAT_TOKEN="YOUR_TOKEN"
curl -s http://localhost/amcat/index/ \
-H "Authorization: Bearer ${AMCAT_TOKEN}"We can first list all available indexes, as a document collection is called in Elasticsearch and thus in AmCAT:
list_indexes()amcat.list_indices()curl -s http://localhost/amcat/index/You can see that the test index we added in the Data Layer section is here and that it is called “state_of_the_union”. To see everyone who has been granted access to an index we can use:
list_index_users(index = "state_of_the_union")amcat.list_index_users(index="state_of_the_union")curl -s http://localhost/amcat/index/state_of_the_union/usersWe will learn more about these roles in the chapter on access management. To see what an index looks like, we can query it leaving all fields blank to request all data at once:
sotu <- query_documents(index = "state_of_the_union", queries = NULL, fields = NULL)
str(sotu)sotu = list(amcat.query("state_of_the_union", fields=None))
print(len(sotu))
for k, v in sotu[1].items():
print(k + "(" + str(type(v)) + "): " + str(v)[0:100] + "...")To not clog the output, we save it into file and display only the beginning:
curl -s http://localhost/amcat/index/state_of_the_union/documents > sotu.json
# show the first few characters only
head -c 150 sotu.jsonKnowing now what a document should look like in this index, we can upload a new document to get familiar with the process:
new_doc <- data.frame(
title = "test",
text = "test",
date = as.Date("2022-01-01"),
president = "test",
year = "2022",
party = "test",
url = "test"
)
upload_documents(index = "state_of_the_union", new_doc)from datetime import datetime
new_doc = {
"title": "test",
"text": "test",
"date": datetime.strptime("2022-01-01", '%Y-%m-%d'),
"president": "test",
"year": "2022",
"party": "test",
"url": "test"
}
amcat.upload_documents("state_of_the_union", [new_doc])curl -s -X POST http://localhost/amcat/index/state_of_the_union/documents \
-H "Content-Type: application/json" \
-d '{
"documents":[
{
"title":"test",
"text":"test",
"date":"2022-01-01",
"president":"test",
"year":"2022",
"party":"test",
"url":"test"
}
]
}'Let’s see if the the new document is in the index:
query_documents(index = "state_of_the_union", fields = NULL, filters = list(title = "test"))import pprint
pp = pprint.PrettyPrinter(depth=4)
res=list(amcat.query("state_of_the_union", fields=None, filters={"title": "test"}))
pp.pprint(res)curl -s -X POST http://localhost/amcat/index/state_of_the_union/query \
-H 'Content-Type: application/json' \
-d '{"filters":{"title":["test"]}}' | jq -r ".results"We will learn more about queries later on in the Writing a Query chapter.
Instead of adding whole documents, you can also change fields in an index. Fields are similar to columns in a table in Excel. However, you need to define the type of a field upon its creation and make sure that you later only add data which adheres to the specifications of the type (otherwise you will get an error). To learn more about the fields in the test index, you can use:
get_fields(index = "state_of_the_union")amcat.get_fields("state_of_the_union")curl -s http://localhost/amcat/index/state_of_the_union/fieldsYou can see that there are five different types in this index: date, keyword, text, url and double. Keyword, text, url are all essentially the same type in R, namely character strings. The date needs to be a POSIXct class, which you can create with as.Date. Year should be a double, i.e., a numeric value or integer.
You can add new fields to this, for example, if you want to add a keyword to the documents:
set_fields(index = "state_of_the_union", list(keyword = "keyword"))amcat.set_fields("state_of_the_union", {"keyword":"keyword"})curl -s -X POST http://localhost/amcat/index/state_of_the_union/fields \
-H 'Content-Type: application/json' \
-d '{"keyword":"keyword"}'When you now query a document, however, you will not see this new field:
query_documents(index = "state_of_the_union", fields = NULL, filters = list(title = "test"))res = list(amcat.query("state_of_the_union", fields=None, filters={"title": "test"}))
pp.pprint(res)curl -s -X POST http://localhost/amcat/index/state_of_the_union/query \
-H 'Content-Type: application/json' \
-d '{"filters":{"title":["test"]}}' | jq -r ".results"This is because it is empty for this document, just as the url field, which is absent from all documents in this index. We can add something to the new field and see if it shows up:
update_tags(index = "state_of_the_union",
action = "add",
field = "keyword",
tag = "test",
filters = list(title = "test"))query_documents(index = "state_of_the_union",
fields = c("title", "keyword"),
filters = list(title = "test"))test_doc = list(amcat.query("state_of_the_union", fields=["id"], filters={"title": "test"}))[0]
amcat.update_document("state_of_the_union", doc_id=test_doc["_id"], body={"keyword": "test"})res=list(amcat.query("state_of_the_union", fields=["title", "keyword"], filters={"title": "test"}))
pp.pprint(res)test_doc=$(curl -s -X POST http://localhost/amcat/index/state_of_the_union/query \
-H 'Content-Type: application/json' \
-d '{"filters":{"title":["test"]}}' | jq -r ".results[]._id")
curl -s -X PUT http://localhost/amcat/index/state_of_the_union/documents/${test_doc} \
-H 'Content-Type: application/json' \
-d '{"keyword": "test"}'curl -s -X POST http://localhost/amcat/index/state_of_the_union/query \
-H 'Content-Type: application/json' \
-d '{"filters":{"title":["test"]}}' | jq -r ".results"Now that we have a better idea of what an index is and how it looks like, we can create a new one>
create_index(index = "new_index", guest_role = "admin")
list_indexes()
get_fields(index = "new_index")amcat.create_index(index="new_index", guest_role="admin")amcat.list_indices()
amcat.get_fields("new_index")curl -s -X POST http://localhost/amcat/index/ \
-H 'Content-Type: application/json' \
-d '{
"name": "new_index",
"guest_role": "ADMIN"
}'curl -s http://localhost/amcat/index/
curl -s http://localhost/amcat/index/new_index/fieldsAs you can see, the newly created index already contains fields. You could now manually define new fields to fit your data. Or you can simply start uploading data:
new_doc <- data.frame(
title = "test",
text = "test",
date = as.Date("2022-01-01"),
president = "test",
year = "2022",
party = "test",
url = "test"
)
upload_documents(index = "new_index", new_doc)get_fields(index = "new_index")new_doc = {
"title": "test",
"text": "test",
"date": datetime.strptime("2022-01-01", '%Y-%m-%d'),
"president": "test",
"year": "2022",
"party": "test",
"url": "test"
}
amcat.upload_documents("new_index", [new_doc])amcat.get_fields("new_index")curl -s -X POST http://localhost/amcat/index/new_index/documents \
-H "Content-Type: application/json" \
-d '{
"documents":[
{
"title":"test",
"text":"test",
"date":"2022-01-01",
"president":"test",
"year":"2022",
"party":"test",
"url":"test"
}
]
}'curl -s http://localhost/amcat/index/new_index/fieldsamcat4 guesses the types of fields based on the data. You can see here that this might not be the best option if you care about data types: party and president have been created as text, when they should be keywords; year is now a long type instead of double or integer.
Finally, we can also delete an index:
delete_index(index = "new_index")amcat.delete_index("new_index")curl -s -X DELETE http://localhost/amcat/index/new_index3.2.1 A Note on the ID Field and Duplicated Documents
AmCAT indexes can have all kinds of fields, yet one special field must be present in every document of every index: a unique ID. This ID is usually not that noteworthy, since the user does not really need to take care of it. This changes, however, with the special case of duplicated documents, that is, a document with the exact same information in the same fields. AmCAT does not normally check if your documents are duplicated when you upload them. However, when no ID is present in an uploaded document, as in the example we uploaded above, AmCAT will construct a unique ID from the available data of a document. Let us have another look at that document we titled “test”:
query_documents(index = "state_of_the_union", fields = NULL, filters = list(title = "test"))res=list(amcat.query("state_of_the_union", fields=None, filters={"title": "test"}))
pp.pprint(res)curl -s -X POST http://localhost/amcat/index/state_of_the_union/query \
-H 'Content-Type: application/json' \
-d '{"filters":{"title":["test"]}}' | jq -r ".results"Note that AmCAT has automatically added an _id field (in R it is .id due to naming conventions) to the document. If we would upload the same document again, the algorithm that constructs the _id field would come up with the same value and the document would be replaced by the newly uploaded document. If we wanted to keep a duplicate for some reason, we could accomplish that by either changing at least one value in a field or by assigning an ID column manually:
new_doc <- data.frame(
.id = "1",
title = "test",
text = "test",
date = as.Date("2022-01-01"),
president = "test",
year = "2022",
party = "test",
url = "test"
)
upload_documents(index = "state_of_the_union", new_doc)query_documents(index = "state_of_the_union", fields = NULL, filters = list(title = "test"))from datetime import datetime
new_doc = {
"_id": "1",
"title": "test",
"text": "test",
"date": datetime.strptime("2022-01-01", '%Y-%m-%d'),
"president": "test",
"year": "2022",
"party": "test",
"url": "test"
}
amcat.upload_documents("state_of_the_union", [new_doc])res=list(amcat.query("state_of_the_union", fields=None, filters={"title": "test"}))
pp.pprint(res)curl -s -X POST http://localhost/amcat/index/state_of_the_union/documents \
-H "Content-Type: application/json" \
-d '{
"documents":[
{
"_id": "1",
"title":"test",
"text":"test",
"date":"2022-01-01",
"president":"test",
"year":"2022",
"party":"test",
"url":"test"
}
]
}'curl -s -X POST http://localhost/amcat/index/state_of_the_union/query \
-H 'Content-Type: application/json' \
-d '{"filters":{"title":["test"]}}' | jq -r ".results"As you can see, we now have the example document in the index twice – although with different IDs. To simulate what would have happened without an ID, or rather if the ID had been constructed automatically, we can upload different data, but with the same ID to see what changes:
new_doc <- data.frame(
.id = "1",
title = "test",
text = "A second test",
date = as.Date("2022-01-02"),
president = "test",
year = "2022"
)
upload_documents(index = "state_of_the_union", new_doc)query_documents(index = "state_of_the_union", fields = NULL, filters = list(title = "test"))from datetime import datetime
new_doc = {
"_id": "1",
"title": "test",
"text": "A second test",
"date": datetime.strptime("2022-01-02", '%Y-%m-%d'),
"president": "test",
"year": "2022"
}
amcat.upload_documents("state_of_the_union", [new_doc])res=list(amcat.query("state_of_the_union", fields=None, filters={"title": "test"}))
pp.pprint(res)curl -s -X POST http://localhost/amcat/index/state_of_the_union/documents \
-H "Content-Type: application/json" \
-d '{
"documents":[
{
"_id": "1",
"title":"test",
"text":"A second test",
"date":"2022-01-02",
"president":"test",
"year":"2022"
}
]
}'curl -s -X POST http://localhost/amcat/index/state_of_the_union/query \
-H 'Content-Type: application/json' \
-d '{"filters":{"title":["test"]}}' | jq -r ".results"The document with the ID 1 has been replaced with the new data. This is the normal behaviour of AmCAT: when we tell it to add data to an already present document, identified by the ID, it will be replaced. If a field was present in the old document, but not in the data it is replaced with, this field will be empty afterwards.