9 About amcat
AmCAT has been in development in various guises since about 2001 as a text research / content analysis platform at the VU. From the start, the core has been a database of news articles, an API allows other programs and power users to connect to it directly from e.g. Python or R and an intuitive query interface for performing quantitative analysis. The screenshots below give some indication of the database and query interface of AmCAT 3.5.
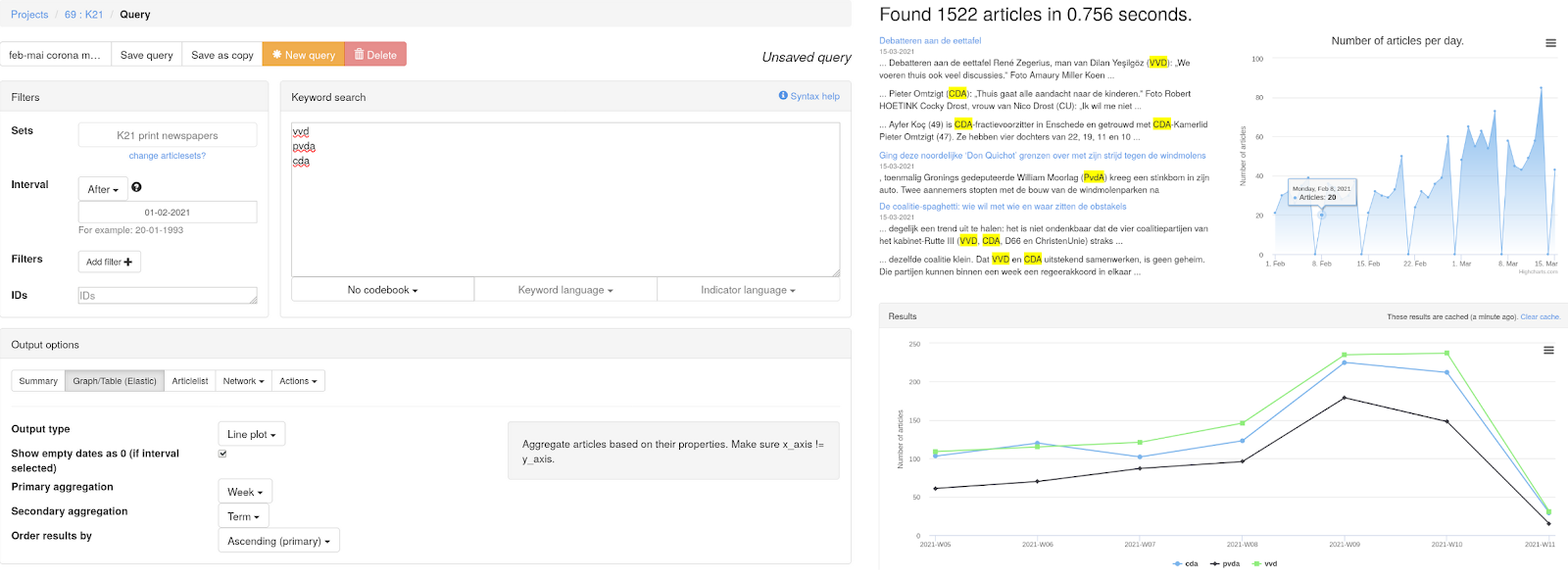
In the last 20 years, the availability of user friendly tools for text analysis has greatly increased. Many proprietary platforms like LexisNexis or Coosto allow basic text analysis directly on the dashboard, while R and Python based toolkits like quanteda (Benoit et al. 2018) and scikit-learn (Pedregosa et al. 2011) have put very powerful analysis possibilities within the reach of a technically inclined social scientist. However, even with those advances we believe that a tool such as AmCAT can still play an important role for text analysis in the social sciences:
- An intuitive user interface gives a visual overview of the stored texts and allows non-technical users to interact with the system, without restricting its use to a single proprietary platform. This also makes it a valuable resource in teaching quantitative content analysis.
- A shared storage format, and API makes it easier to share and reuse tools and analysis scripts. It also aids reproducible science by allowing analyses and data to be shared and validated based on immutable data sets.
- Finally, as communication science data is often proprietary, fine-grained access control allows results to be shared and validated without giving access to the underlying data using non-consumptive research.
This is, why AmCAT was redesigned within work package 7 of the OPTED (Observatory for Political Texts in European Democracies: A European research infrastructure) project. The goal of the redesign is to create an infrastructure that is simple and flexible enough to be adapted for various projects at OPTED partner universities, other research insitutions and by basically everyone interested in text analysis.